上周五经历了一场半夜起来处理现场问题的事,从早上1点多搞到4点多。总结一下。
遇到现场问题的时候:尽可能的保存现场很重要。打dump,查活动进程,看当前运行SQL,当前具体环境信息。在保存好现场之后可以从如下三个方面来提问:
- 是否是最近修改代码问题,尽快回滚最近发布
- 是否环境问题,最近是否有硬件升级。能否创建新实例来隔绝可能的环境问题
- 是否数据问题,包括脏数据,有问题的配置等
问题
出现问题的时候,在重新Recycle IIS的Application Pool之前,先dump了w3wp.exe进程,通过下面的Dump分析找到了出问题的URL:
- 通过!runaway,找到了运行时间最长线程的线程号。
- 在WinDbg中加载NetExt扩展,使用!whttp命令,找到了出问题线程对应的HttpContext和其URL。
通过观察URL,找到了出问题的对应物件的ID,原因是这个ID的ParentID是其自身,所以造成了循环引用。属于数据问题。又通过!wdo HttpContext来查看HttpContext找到了对应的用户信息。
进一步思考
为什么一个死循环会卡死整个应用?IIS不是给每个request新建一个Context然后放到独立的线程中运行的吗?理论上即使上面有问题的ID卡死了当前线程,那么接下来的request应该能得到正常执行,而不是卡死。
最终通过调查找到原因:在应用程序代码使用Application.Lock()而忘记释放导致的。最终的释放是IIS在Pipeline处理完成后自动无条件释放所有锁,所以卡顿的request结束后,接下来的request才有机会继续执行。
.NET中的死锁分析
死锁简单来说就是:想要的得不到。
通常有两种情况造成死锁:
- 循环等待,我拥有A锁,等待B锁。你拥有B锁,等待A锁。双方都没有放手(设置Timeout)。
- 我拿着锁一直不放。你们都没有办法获取,只能等待,造成死锁。
对于循环持有锁的情况,在WinDbg中加载SOSEX,再使用!dlk命令会自动搜索这种死锁。
对于锁着不放情况,调查死锁的方法是:
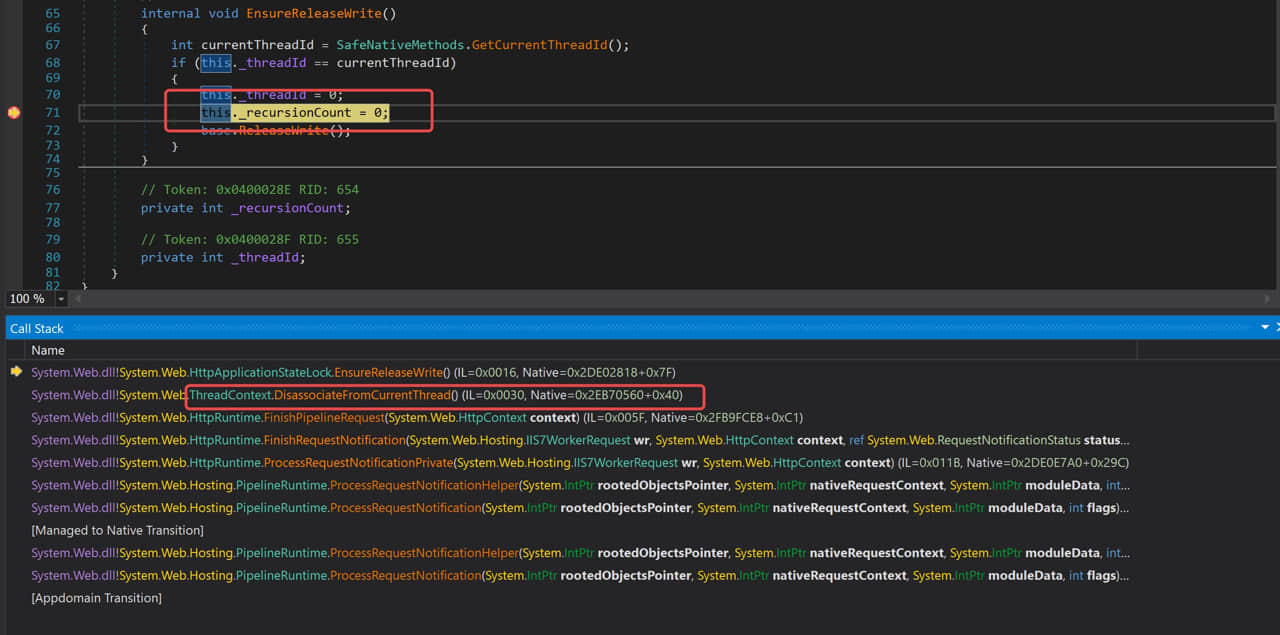
- 找到等待/持有这个锁的线程,可以使用~*e!clrstack查看所有线程调用栈,通常是卡在System.Threading.Monitor类型Enter/Wait方法上。
- 如果是等待锁,那么谁持有这个锁?可以通过
- 查看当前线程的调用栈和参数!clrstack -p,哪个对象在获取锁,!do 查看这个对象能得到更多信息。比如HttpApplicationStateLock会记录当前持有者的线程id。
- 或者!SyncBlk -all看看你关注持有锁的对象。
- 通过~[thread id]s跳掉持有锁的线程,看看当前线程在做什么,为什么不释放,通常到这里就找到问题了。
Comments: